[프로그래머스/파이썬] 디스크 컨트롤러 풀이
(heap, 힙, sort, heapq, heappush, heappop)
1. 문제
https://school.programmers.co.kr/learn/courses/30/lessons/42627
프로그래머스
SW개발자를 위한 평가, 교육, 채용까지 Total Solution을 제공하는 개발자 성장을 위한 베이스캠프
programmers.co.kr
2. 문제 이해
2.1. 문제 요약
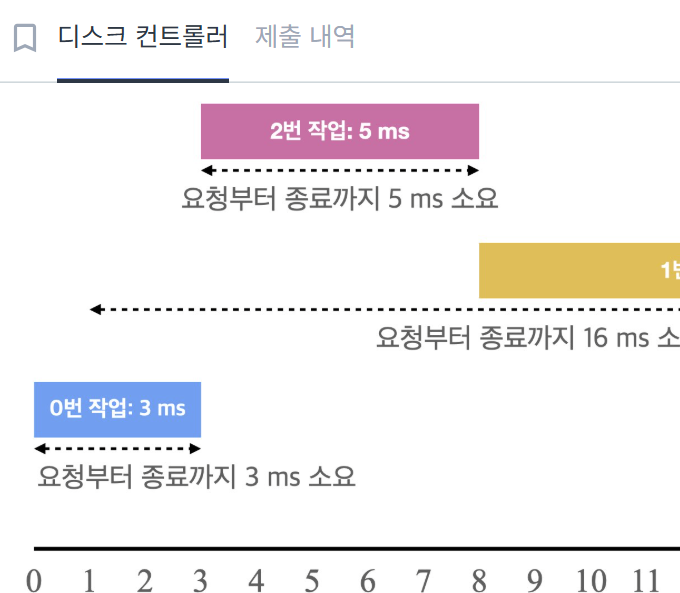
하드디스크는 한 번에 하나의 작업만 수행할 수 있다.
따라서 여러 개의 작업이 들어왔을 때 우선순위에 따라 작업을 수행하도록 하는, '디스크 컨트롤러'를 구현하여
총작업의 반환 시간의 평균 구해야 한다.
2.2. 디스크 컨트롤러 규칙
- 대기 큐 : [ [작업 번호, 작업 요청 시각, 작업 소요 시간] ] 저장
- 작업을 시키는 기준
- 하드디스크가 작업을 하고 있지 않고
- 대기 큐가 비어있지 않다면
- → 가장 우선순위가 높은 작업을 꺼내서 작업.
- 우선순위 기준 : # 작업의 소요시간이 짧은 것 > 작업의 요청 시각이 빠른 것 > 작업의 번호가 작은 것 순
- 하드디스크 작업 수행 : 한번 시작하면 끝날 때까지 그 작업만 수행
- 추가 특징
- 작업 마치는 시점 ↔ 다른 작업이 들어오는 시점이 겹친다면,
- 하드디스크가 작업을 마치자마자 요청이 들어온 작업을 대기 큐에 저장한 뒤, 우선순위가 높은 작업을 대기 큐에서 꺼내서 하드디스크에 작업 시킴
- 작업을 마치는 시점, 다른 작업이 들어오지 않더라도
- 작업을 마치자마자 또 다른 작업을 시작할 수 있다.
- 작업 마치는 시점 ↔ 다른 작업이 들어오는 시점이 겹친다면,
2.3. 반환 시간 계산

- 반환 시간 = 요청 시각 - 작업 종료 시각 ( 여기서 요청 시각은 jobs 배열에 있는 그대로, 처음 요청 들어온 시각)
- 반환 시간의 평균 = 각 작업당 반환 시간의 합계 / 작업 횟수
3. 문제 해결 아이디어
1. jobs를 오름차순 정렬 해준다.
- jobs는 [작업이 요청되는 시점, 작업의 소요시간]으로 구성되어 있다. (2차원 배열)
- 무조건 처음 input이 작업 요청 시점이 빠른 게 있다는 보장이 되어 있지 않으므로, 요청 시점 기준으로 정렬을 진행한다.
2. 대기 큐를 만들 때, heap 자료구조를 이용하여 우선순위대로 작업을 꺼내올 수 있게 만든다.
- 우선순위 기준은 작업의 소요시간이 짧은 것 > 작업의 요청 시각이 빠른 것 > 작업의 번호가 작은 것 순이다.
- 따라서 대기 큐를 만들 때 [[ 작업 소요시간, 작업 요청 시각 ],... ]으로 구성된 2차원 배열을 만들어준다.
3. 디스크 컨트롤러 작업 수행을 위해 jobs와 대기 큐(힙)에 있는 작업이 모두 사라질 때까지 무한 반복한다.
- 모든 작업을 수행해야 끝나기 때문
3.1. 현재 시각을 기준으로 지금 시점 전에 들어온 작업들은 대기큐에 넣어 주는 것을 반복한다. (2중 반복문)
- jobs 배열에서는 [0] 번째 값을 pop 한다
- 대기 큐 힙에서는 jobs에서 뺀 값을 push 한다. (이때, 우선순위에 따라 [ 작업 소요시간, 작업 요청 시각 ]으로 구성되게 push한다. (2번 참고) )
4. 나머지 각 작업별 반환시간들을 계산하면 된다.
3. 코드
import heapq
import math
# 작업의 소요시간이 짧은 것 > 작업의 요청 시각이 빠른 것 > 작업의 번호가 작은 것 순
def solution(jobs): # [작업이 요청되는 시점, 작업의 소요시간]
# 1. 변수 선언
answer = 0 # 우선순위 디스크 컨트롤러가 이 작업을 처리했을 때 모든 요청 작업의 반환 시간의 평균
nowTime= 0 # 현재 시간
endTime = 0 # 작업 종료 시각
returnTimes = 0 # 반환 시간 합계
jobsLen = len(jobs) # 반환시간 개수
readyQueue = [] # 대기 큐 (우선순위로 꺼내야하므로 힙으로 만든다.)
heapq.heapify(readyQueue)
# 2. jobs 오름차순 정렬. 시간별로 꺼내야하므로 시간이 빠른게 앞에 가도록 한다.
jobs.sort()
# 3. 디스크 컨트롤러 작업 수행 - 들어올 jobs와 대기큐에 작업이 남아있을때까지
while jobs or readyQueue :
# 3.1. 현재 시간에 맞는 작업 요청 대기큐에 넣기 (다 넣을때까지 반복 )
while jobs and nowTime >= jobs[0][0] : # 남은 작업 요청이 있고, 현재 시간 전에 왔다면
# 3.1.1. 대기 큐에 현재 작업을 꺼내서 넣는다.
nowJob = jobs.pop(0)
# 작업의 소요시간이 짧은 것 > 작업의 요청 시각이 빠른 것 > 작업의 번호가 작은 것 순
heapq.heappush(readyQueue, [nowJob[1], nowJob[0]]) #[ 작업 소요시간, 작업 요청 시각 ] (우선순위)
# 3.2. 대기 큐에 작업이 있다면, 그 작업을 진행한다.
if readyQueue:
# 3.2.1. 우선순위에 따라 작업 하나를 꺼내고, 요청시각&작업종료시각&반환시간을 구한다.
nowjob = heapq.heappop(readyQueue) #[ 작업 소요시간, 작업 요청 시각 ]
endTime = nowTime + nowjob[0] # 작업 종료 시간 (현재시간 + 작업 요청 시각)
returnTimes += (endTime - nowjob[1]) #반환 시간 더하기 (종료시각 - 자기 자체 '요청' 시각)
nowTime = endTime # 현재 시간을 종료 시각으로 업데이트
# 3.3. 대기 큐에 작업이 없다면, 그냥 1초 흐른다.
else:
nowTime += 1
# 4. 반환시간의 평균 구하기 (정수)
answer = returnTimes // jobsLen
return answer
4. 코드 풀이
1. 변수 선언
# 1. 변수 선언
answer = 0 # 우선순위 디스크 컨트롤러가 이 작업을 처리했을 때 모든 요청 작업의 반환 시간의 평균
nowTime= 0 # 현재 시간
endTime = 0 # 작업 종료 시각
returnTimes = 0 # 반환 시간 합계
jobsLen = len(jobs) # 반환시간 개수
readyQueue = [] # 대기 큐 (우선순위로 꺼내야하므로 힙으로 만든다.)
heapq.heapify(readyQueue)
- 현재 시간, 작업 종료 시간, 반환 시간, 반환 개수로 각 반환 시간을 계산하기 위한 변수 선언
- 대기 큐를 구현하기 위해 heap 라이브러리로 힙 만들기
** heapq.heapify ( 힙 ) : 힙 생성 함수
2. jobs 배열 오름차순 정렬
# 2. jobs 오름차순 정렬. 시간별로 꺼내야하므로 시간이 빠른게 앞에 가도록 한다.
jobs.sort()- jobs는 [작업이 요청되는 시점, 작업의 소요시간]으로 구성되어 있다. (2차원 배열)
- 무조건 처음 input이 작업 요청 시점이 빠른 게 있다는 보장이 되어 있지 않으므로, 요청 시점 기준으로 정렬을 진행한다.
3. jobs 배열과 대기 큐에 작업이 있을 때까지 무한반복 한다.
# 3. 디스크 컨트롤러 작업 수행 - 들어올 jobs와 대기큐에 작업이 남아있을때까지
while jobs or readyQueue :
3.1 현재 시간까지 들어올 수 있는 작업이 있다면 대기 큐에 넣는 것을 계속 반복한다.
# 3.1. 현재 시간에 맞는 작업 요청 대기큐에 넣기 (다 넣을때까지 반복 )
while jobs and nowTime >= jobs[0][0] : # 남은 작업 요청이 있고, 현재 시간 전에 왔다면
# 3.1.1. 대기 큐에 현재 작업을 꺼내서 넣는다.
nowJob = jobs.pop(0)
# 작업의 소요시간이 짧은 것 > 작업의 요청 시각이 빠른 것 > 작업의 번호가 작은 것 순
heapq.heappush(readyQueue, [nowJob[1], nowJob[0]]) #[ 작업 소요시간, 작업 요청 시각 ] (우선순위)- jobs 배열에서는 첫 번째 값 ([0])을 pop 한다
- 대기 큐 힙에서는 jobs에서 뺀 값을 push 한다.
(이때, 우선순위에 따라 [ 작업 소요시간, 작업 요청 시각 ]으로 구성되게 push한다. )
** 파이썬 힙은 0번 인덱스부터 우선순위를 가지기 때문이다. | (a, b) 라면 a->b 순 |
3.2 대기 큐의 작업 유무에 따라 계산을 진행한다.
# 3. 디스크 컨트롤러 작업 수행 - 들어올 jobs와 대기큐에 작업이 남아있을때까지
while jobs or readyQueue :
( ... 대기 큐에 작업 추가 로직 생략 .. )
# 3.2. 대기 큐에 작업이 있다면, 그 작업을 진행한다.
if readyQueue:
# 3.2.1. 우선순위에 따라 작업 하나를 꺼내고, 요청시각&작업종료시각&반환시간을 구한다.
nowjob = heapq.heappop(readyQueue) #[ 작업 소요시간, 작업 요청 시각 ]
endTime = nowTime + nowjob[0] # 작업 종료 시간 (현재시간 + 작업 요청 시각)
returnTimes += (endTime - nowjob[1]) #반환 시간 더하기 (종료시각 - 자기 자체 '요청' 시각)
nowTime = endTime # 현재 시간을 종료 시각으로 업데이트
# 3.3. 대기 큐에 작업이 없다면, 그냥 1초 흐른다.
else:
nowTime += 1
1. 대기 큐 (readyQueue)에 작업이 있다면, 작업을 꺼낸다
- 작업 종료 시간을 구하고, 반환 시간을 구해서 합계 값을 업데이트해 준다. (returnTimes)
- 현재 시간을 종료 시간으로 업데이트한다.
2. 대기 큐 (readyQueue)에 작업이 없다면,
- 그냥 1초를 흘러가게 한다. (nowTime +1 )
4. 반환 시간의 평균을 구한다 (정수로)
# 4. 반환시간의 평균 구하기 (정수)
answer = returnTimes // jobsLen
정수로 구해야하므로, 바로 몫만 구해주는 // 를 사용했다.
4. 마무리

이 문제는 3번째 푸는 문제이다.
3번째로 푸니까 드디어 풀이 없이 스스로 풀 수 있게 됐고 풀이를 설명할 수 있게 됐다..
그리고 작업 스케줄링 문제가 나올 때는 힙이 필요하다는 것을 90% 정도 이해하게 된 것 같다.
또 문제 이해하는데도 정말 오래 걸렸다.
알고리즘은 문제이해 40% 문제풀기 60%인 것 같다..
참고 : 상세히 이해하기 위해 GPT에게 물어봤다.
힙을 써야 하는 이유
작업의 대기 시간이 작업의 처리 순서에 따라 달라지기 때문에, 처리할 수 있는 작업이 여러 개일 때 가장 적합한 작업을 먼저 선택하여 처리하는 것이 중요합니다.
이 문제에서 요구하는 것은 전체 대기 시간을 최소화하는 것이므로, 처리할 수 있는 작업을 가장 빠르게 종료할 수 있는 순서로 처리하는 전략이 필요합니다.
힙의 특성상, 각 작업을 빠르게 우선순위대로 처리할 수 있어, 시간 복잡도를 줄이고 최적화된 작업 처리 순서를 유지할 수 있습니다.
단순 이중 정렬로 해결할 수 없는 이유
이 문제는 단순히 요청 시점이나 소요 시간에 기반한 정렬로 해결할 수 없습니다. 왜냐하면 작업을 처리하는 순서가 그 자체로 전체 대기 시간에 영향을 미치기 때문입니다.
이중 정렬에서는 두 기준을 기준으로 정렬할 수 있지만, 작업을 처리하는 순서가 변하면서 그 후속 작업의 대기 시간이 어떻게 달라지는지에 대한 고려가 부족합니다.
읽어주셔서 감사합니다~
도움이 되셨다면 공감 부탁드립니다 😊
'코딩테스트 > 파이썬' 카테고리의 다른 글
| [프로그래머스/파이썬] 입국심사 풀이 (이진탐색, 이분탐색, python) (0) | 2025.05.16 |
|---|---|
| [프로그래머스/파이썬] 이중우선순위큐 풀이 (힙, Python, heap, heapq) (0) | 2025.05.15 |
| [프로그래머스/파이썬/JS] 게임 맵 최단걸이 풀이 (bfs, deque, python, deepcopy, JavaScript, 자바스크립트) (0) | 2025.05.09 |
| [프로그래머스/파이썬] 타겟 넘버 중복순열 풀이 (Python, product, 반복문) (0) | 2025.05.08 |
| [프로그래머스/파이썬] 전력망을 둘로 나누기 풀이 (dfs, 완전탐색, python) (0) | 2025.05.06 |




댓글